Substack-Nutzer diskutieren WhatsApp-Datenschutz auf einer Plattform mit Klartext-E-Mails im Quellcode, ungesalzenem MD5-Hashing und einem Data Breach von 700.000 Datensätzen.
Auf Substack diskutieren Menschen leidenschaftlich über die Datenschutzprobleme von WhatsApp und Meta. Sie warnen sich gegenseitig vor Tracking, vor Profiling, vor dem gläsernen Menschen. Was sie dabei übersehen: Die Plattform, auf der sie diese Diskussion führen, hat ein mindestens ebenso gravierendes Problem und wurde vor fünf Tagen Opfer eines massiven Data Breaches.
Der Auslöser
Ein Substack-Nutzer stellte die Frage in die Runde: „Wer von euch benutzt WhatsApp und wieso?” Es folgte eine engagierte Diskussion über Meta, Datenschutz, Verschlüsselung und Alternativen wie Signal oder Telegram. Berechtigte Kritik, keine Frage. Aber niemand stellte die offensichtliche Gegenfrage: Wie steht es eigentlich um die Plattform, auf der wir das gerade diskutieren?
Ich habe nachgeschaut. Was ich gefunden habe, ist ernüchternd.
Der Blacklight-Test: Trügerische Sauberkeit
Mein erster Schritt war ein Scan mit Blacklight, dem Real-Time Website Privacy Inspector von The Markup. Das Ergebnis: „Auf dieser Website wurden keine Ad-Tech-Unternehmen gefunden.”

Klingt gut. Ist es aber nicht.
Blacklight scannt nur die Website und zwar ohne Cookies zu akzeptieren. Aus der EU aufgerufen, greift die DSGVO: Tracker werden erst nach explizitem Consent geladen. Zusätzlich erkennt Substacks Bot-Detection möglicherweise den Scanner und liefert die Tracker gar nicht erst aus.
Das eigentliche Problem liegt woanders: Das heftigste Tracking bei Substack findet nicht auf der Website statt, sondern in den E-Mails und in der First-Party-Datensammlung. Beides sieht Blacklight nicht.
Ein Blick mit Little Snitch, einer macOS-Firewall, die ausgehende Netzwerkverbindungen protokolliert, zeigt ein anderes Bild: 7 Tracker für substack.com, darunter doubleclick.net (Googles Werbenetzwerk), google-analytics.com, googletagmanager.com und youtube-nocookie.com (das trotz des Namens Tracking ermöglicht). Little Snitch arbeitet auf Systemebene – da helfen weder Bot-Detection noch DSGVO-Consent-Dialoge.
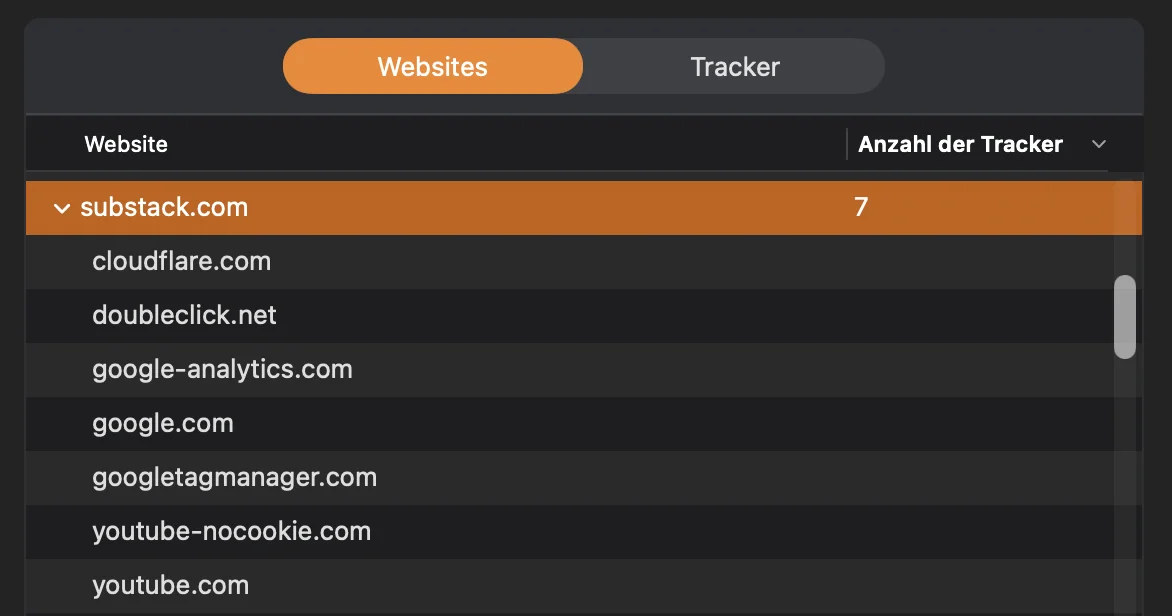
Der Blick in den Quellcode: F12 reicht
Wer auf einer Substack-Seite die Entwicklertools öffnet (F12), findet im Quellcode ein globales JavaScript-Objekt namens window._analyticsConfig. Dort steht bei eingeloggten Nutzern:
- Voller Name im Klartext
- E-Mail-Adresse im Klartext
- User-ID als numerischer Wert
- Land und Sprache des Nutzers
- Eine angeblich „anonyme” ID die direkt neben dem Klarnamen steht
Dazu kommen drei weitere Felder, die es in sich haben:
-
localGaPixelId– ein Google Analytics 4 Pixel, direkt von Substack eingebunden -
adwordsAccountId– eine Google Ads Konto-ID -
adwordsEventSendTo– Google Ads Conversion Tracking
Das bedeutet: Substack meldet Seitenaktivität an Google, verknüpft mit einem Identifier, der in deinem Browser eindeutig dir zugeordnet ist. Und diese Daten liegen als globales JavaScript-Objekt vor. Zugänglich für jedes Script, das auf der Seite läuft, einschließlich der Third-Party-Pixel, die Creator optional einbinden können.
Besonders brisant ist das Feld anonymousId. Der Name suggeriert Anonymität. Ein schneller Test im Terminal beweist das Gegenteil:
$ echo -n "meinemail@example.com" | md5sum
9fc6ddcbb5b82d83a5bba78820ed79b9 -

Die anonymousId ist nichts anderes als der ungesaltene MD5-Hash der E-Mail-Adresse. MD5 gilt seit über einem Jahrzehnt als kryptografisch gebrochen. Öffentlich zugängliche Rainbow Tables enthalten Milliarden vorberechneter Hashes. Gängige E-Mail-Adressen lassen sich in Sekundenbruchteilen zurückrechnen. Kein Salt, kein HMAC, einfach roher MD5.
Dieser „anonyme” Identifier wird zusammen mit Substacks Google Analytics Pixel und Google Ads Conversion Tracking bei jedem Seitenaufruf an Google übermittelt. Google erhält also einen Identifier, der trivial zur echten E-Mail-Adresse des Nutzers zurückgerechnet werden kann.
Substack nennt es anonymousId. Das ist ungefähr so, als würde man seinen Namen rückwärts schreiben und behaupten, das sei jetzt ein Pseudonym.
Um fair zu bleiben: Die Datenübertragung zwischen Browser und Server läuft über HTTPS, ist also transportverschlüsselt. Das Problem ist nicht die Übertragung. Es ist die clientseitige Exposition dieser Daten im JavaScript-Scope und die Weitergabe eines trivial deanonymisierbaren Identifiers an Google.
Das E-Mail-Tracking: Jeder Klick wird erfasst
Substack bettet in jede Newsletter-E-Mail Tracking-Pixel ein – winzige, unsichtbare 1x1-Pixel-Bilder, die beim Öffnen einer Mail von Substacks Servern geladen werden. So registriert Substack, wann eine E-Mail geöffnet wurde. Selbst E-Mail-Previews im Client reichen dafür aus.
Für Links verwendet Substack ein System, das für jede E-Mail-Adresse einzigartige URLs generiert. Klickt ein Subscriber auf einen Link, wird er kurz über eine Substack-URL geleitet, die den Klick mit seiner Identität verknüpft – bevor er zur eigentlichen Webseite weitergeleitet wird. Laut technischer Analyse sind diese Tracking-Links „die benutzerunfreundlichsten, die ich gesehen habe: ein einziger unentschlüsselbarer Blob”, zlib-komprimiert und base64url-kodiert.
Aus diesen Daten erstellt Substack für jeden Subscriber ein 5-Sterne-Bewertungsprofil: Wer häufig liest und klickt, bekommt fünf Sterne. Wer selten öffnet, eine niedrige Bewertung. Creator können für jeden einzelnen Subscriber einsehen: wann er sich angemeldet hat, welche E-Mails er geöffnet hat, welche Links er angeklickt hat, und wie aktiv er in den letzten 7 Tagen, 30 Tagen und 6 Monaten war.
Substack bietet Creatorn zusätzlich die Möglichkeit, Facebook-Pixel, Twitter/X-Pixel und Google Tag Manager direkt in ihre Publikation einzubauen. Ein Feld in den Einstellungen, ID rein, fertig. Das bedeutet: Selbst wenn Substacks eigenes Tracking jemandem nicht reicht, kann er die volle Ad-Tech-Maschinerie obendrauf packen.
Der Data Breach: 700.000 Datensätze geleakt
Am 5. Februar 2026 vor fünf Tagen, bestätigte Substack-CEO Chris Best einen Datenbreach. Im Oktober 2025 hatte ein unbefugter Dritter Zugriff auf Nutzerdaten erlangt: E-Mail-Adressen, Telefonnummern und „interne Metadaten”. Der Vorfall wurde erst am 3. Februar 2026 entdeckt – vier Monate lang blieb der Zugriff unbemerkt.
Ein Hacker veröffentlichte auf einem Cybercrime-Forum rund 697.313 Datensätze. Laut Sicherheitsforschern umfassen die geleakten Daten neben E-Mail-Adressen und Telefonnummern auch User-IDs, Profilbilder, Biografien und möglicherweise Stripe-IDs des Zahlungssystems.
Die Angreifer nutzten exponierte API-Endpoints mit Token-Reuse-Schwachstellen. Automatisierte Scripts scrapten die Daten über unzureichend gesicherte Schnittstellen. Substack selbst bezeichnet den Angriff als „noisy” er hätte also auffallen können. Tat er aber vier Monate lang nicht.
Wie einfach das funktioniert haben dürfte, zeigt ein Blick auf die User-ID im Quellcode: Sie ist eine sequenzielle numerische ID – ein klassisches Sicherheits-Antipattern namens IDOR (Insecure Direct Object Reference). Wenn die API nicht ordentlich abgesichert ist, muss ein Angreifer nur eine Schleife schreiben, die IDs von 1 aufwärts durchiteriert. Kein raffinierter Hack, kein Zero-Day-Exploit. Eine for-Schleife. Und Substack hat vier Monate nicht bemerkt, dass jemand fast 700.000 Datensätze abgeräumt hat.
Substacks Hinweis, dass keine Passwörter oder Kreditkartendaten betroffen seien, klingt beruhigend. Sicherheitsexperten von KnowBe4 widersprechen: E-Mail-Adressen und Telefonnummern reichen für gezieltes Phishing, SIM-Swap-Angriffe oder Doxxing. Angreifer brauchen keine Passwörter, wenn sie Nutzer über Social Engineering manipulieren können.
Was viele übersehen: Die Stripe-Verbindung
Substack betont, dass keine Kreditkartendaten oder Passwörter betroffen seien. Was in dieser Beruhigungsformel untergeht: Unter den geleakten Daten befinden sich laut mehreren Sicherheitsforschern auch Stripe Customer IDs die Verknüpfung zwischen Substack-Account und dem Zahlungsdienstleister Stripe.
Wer auf Substack ein bezahltes Newsletter betreibt, hat bei Stripe ein vollständiges KYC-Verfahren (Know Your Customer) durchlaufen. Stripe kennt den bürgerlichen Namen, das Geburtsdatum, die Adresse, die Steuer-ID, die Bankverbindung und gegebenenfalls einen Scan des Personalausweises. Die Stripe Customer ID ist der Schlüssel, der den möglicherweise pseudonymen Substack-Account mit dieser verifizierten Realidentität verbindet.
Diese ID liegt jetzt in einem Hackerforum. Sie enthält nicht direkt die Bankdaten – aber sie sagt jedem, der Zugang zu den geleakten Daten hat, exakt, welcher Stripe-Account zu welchem Substack-Profil gehört. In Kombination mit den ebenfalls geleakten E-Mail-Adressen und Telefonnummern ergibt das ein präzises Ziel für Social Engineering und Phishing-Angriffe – nicht gegen irgendwen, sondern gezielt gegen Menschen, die nachweislich Geld über Substack bewegen.
Was eine extra E-Mail und ein Pseudonym bringen
Eine naheliegende Schutzmaßnahme ist, sich mit einer eigens angelegten E-Mail-Adresse und einem Pseudonym anzumelden. Das reduziert die direkte Zuordnung zum eigenen Namen soweit nachvollziehbar.
Was man dabei wissen sollte: Substacks Tracking ist systemisch angelegt. Die Tracking-Pixel in jeder E-Mail, die personalisierten Link-URLs, das 5-Sterne-Subscriber-Scoring all das arbeitet mit der E-Mail-Adresse, die man angegeben hat, egal welche es ist. Die anonymousId ist der MD5-Hash genau dieser Adresse und wird bei jedem Seitenaufruf an Google übermittelt. Wer ein bezahltes Newsletter betreibt, hat über Stripe zusätzlich seinen bürgerlichen Namen, seine Bankverbindung und seine Steuerdaten hinterlegt.
Die extra E-Mail ist also kein schlechter Gedanke. Aber sie ändert nichts daran, wie die Plattform unter der Haube funktioniert.
Do Not Track? Nein danke.
Substacks Privacy Policy macht unmissverständlich klar: Do-Not-Track-Anfragen werden nicht unterstützt. Substack sammelt Informationen über Online-Aktivitäten sowohl während der Nutzung als auch nachdem der Nutzer die Plattform verlassen hat.
Im Privacy Watchdog Rating erreicht Substack 40 von 100 Punkten (Note C). Hauptkritikpunkte: Subscriber-Daten werden für Netzwerk-Empfehlungen genutzt, personenbezogene Daten an Werbepartner und Analytics-Anbieter weitergegeben, und die Aufbewahrung ist potenziell länger als nötig.
Das Gesamtbild
Wer auf Substack über WhatsApp-Datenschutz diskutiert, tut das auf einer Plattform, die:
- persönliche Daten im Klartext im JavaScript-Quellcode exponiert
- die „anonyme” ID als ungesaltenen MD5-Hash der E-Mail generiert – trivial umkehrbar
- Google Ads Conversion Tracking eingebaut hat
- jede geöffnete E-Mail und jeden Klick individuell pro Subscriber trackt
- Creatorn erlaubt, zusätzlich Facebook-, Twitter- und Google-Pixel einzubinden
- sequenzielle User-IDs verwendet – ein Einfallstor für automatisiertes Scraping
- Do Not Track ignoriert
- gerade 700.000 Nutzerdatensätze an Hacker verloren hat
- den Breach vier Monate lang nicht bemerkt hat
Warum ich trotzdem auf Substack poste – und warum das kein Widerspruch ist
Ich nutze Substack. Bewusst. Ich gehe dahin, wo die Leser sind, denn Aufklärung nützt nichts, wenn sie niemand liest.
Aber mein Content gehört mir nicht einer Plattform, die meine E-Mail im Quellcode stehen lässt.
Jeder Artikel, den ich schreibe, wird kryptografisch signiert und über das Nostr-Protokoll publiziert. Von dort wird er auf meine statische Website stevennoack.de deployed. Kein Tracking-Pixel, keine personalisierte URL, keine zentrale Datenbank, die gehackt werden könnte. Nichts zu leaken, weil es nichts zu sammeln gibt.
Substack ist mein Verteilungskanal. Nostr ist meine Quelle der Wahrheit. Wenn Substack morgen meinen Account sperrt, einen weiteren Breach erleidet, oder komplett verschwindet, mein Artikel existiert trotzdem weiter. Dezentral, signiert, unter meiner Kontrolle.
Die Frage ist also nicht, ob man Plattformen nutzen sollte. Die Frage ist, ob man von ihnen abhängig sein sollte.
KI-generierung (Claude/Anthropic) · Quellen: Chatverlauf, Vault, Code
Quellen:
- TechCrunch: Substack confirms data breach affecting email addresses and phone numbers (5. Februar 2026) – https://techcrunch.com/2026/02/05/substack-confirms-data-breach-affecting-email-addresses-and-phone-numbers/
- SecurityWeek: Substack Discloses Security Incident After Hacker Leaks Data (Februar 2026) – https://www.securityweek.com/substack-discloses-security-incident-after-hacker-leaks-data/
- CSO Online: Substack data breach leaks users’ email addresses and phone numbers (Februar 2026) – https://www.csoonline.com/article/4128287/substack-data-breach-leaks-users-email-addresses-and-phone-numbers.html
- FireCompass: Substack Data Breach October 2025 – https://firecompass.com/substack-data-breach/
- Privacy Watchdog: Substack Privacy Review – Score 40/100 – https://terms.law/Privacy-Watchdog/newsletter-platforms/substack/
- Substack Privacy Policy – https://substack.com/privacy
- Substack Support: What are the stars on my Subscribers dashboard? – https://support.substack.com/hc/en-us/articles/6461334789652
- Substack Support: How do I use the subscriber dashboard? – https://support.substack.com/hc/en-us/articles/360058529871
- Substack Support: A guide to Substack metrics – https://support.substack.com/hc/en-us/articles/5320347155860
- Technology Should Be Simple: Substack Email Subscribers (März 2025) – https://www.technologyshouldbesimple.com/p/substack-email-subscribers
- Beng Tan: What’s in email tracking links and pixels? – https://bengtan.com/blog/whats-in-email-tracking-links-and-pixels/
- Substack FAQ: Using Advertising Analytics on Substack – https://faq.substack.com/p/using-advertising-analytics-on-substack
- The Markup: Blacklight – https://themarkup.org/blacklight