Wie ich lokale LLMs über LM Chat und Cloud-KI über einen selbstgebauten Vision-Proxy in Open WebUI vereint habe. Zwei Wege, ein Interface, volle Kontrolle.
Es fing mit Ollama an. Lokale LLMs auf dem eigenen Rechner. Keine Cloud, keine API-Kosten, volle Kontrolle. Die Idee ist bestechend einfach: Modell runterladen, starten, chatten.
Bis die Realität zuschlägt.
Das Hardware-Problem
Mein Arbeitsrechner ist ein iMac. Intel. Keine GPU-Beschleunigung für lokale Modelle. Ollama läuft, aber die Modelle kriechen. Ein 7B-Modell braucht gefühlt ewig für eine Antwort. Von größeren Modellen ganz zu schweigen. Und dann noch der Lüfter. xD
Die Lösung lag im Bett: Ein MacBook mit M1-Chip. Apples hauseigene GPU macht bei lokalen LLMs einen massiven Unterschied. Aber Ollama direkt auf dem MacBook nutzen, während ich am iMac arbeite?
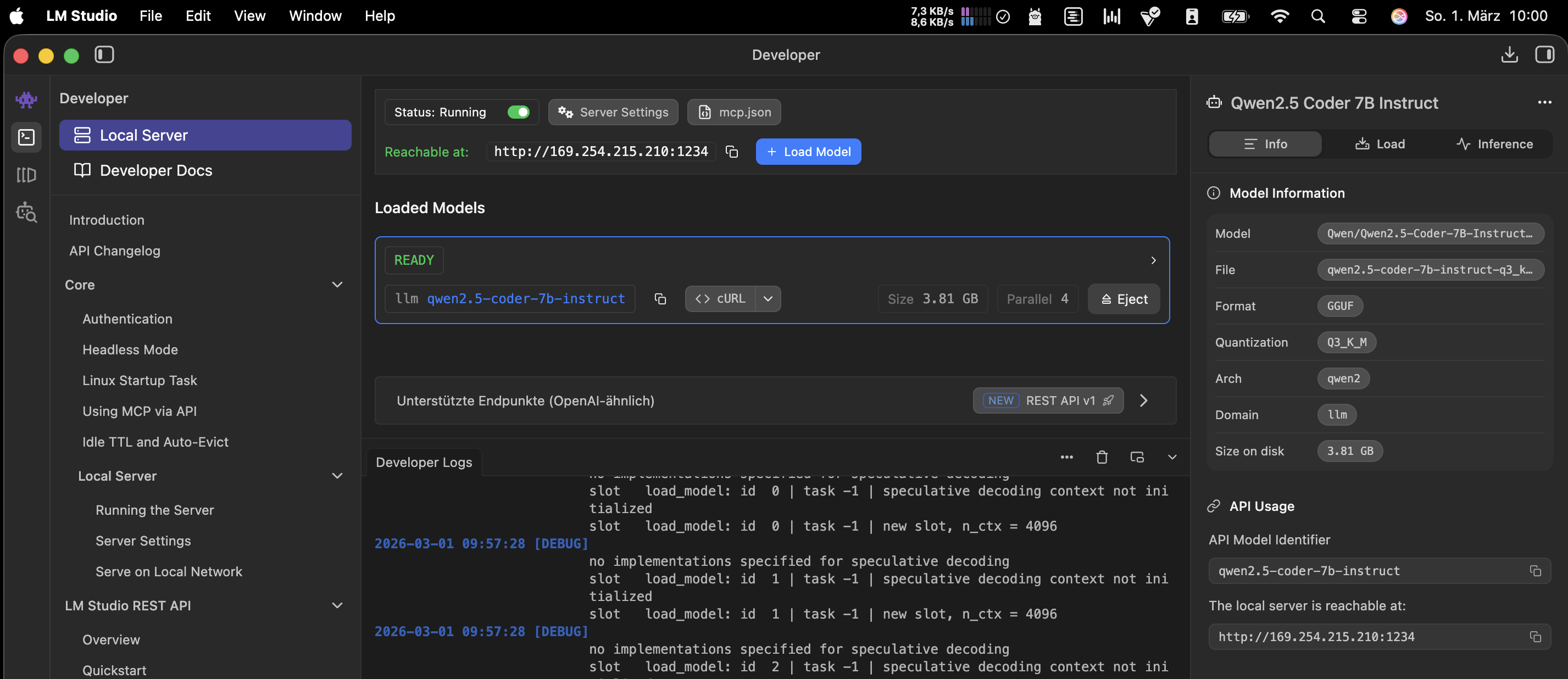
LM Chat - mein LLM Verwalter
LM Chat löst genau dieses Problem. Die App verwaltet lokale Modelle auf dem MacBook, nutzt die M1 GPU, und stellt eine Ollama-kompatible API bereit. Heißt: Mein iMac kann die Modelle auf dem MacBook ansprechen, als würden sie lokal auf Ihnen laufen laufen.
Modelle runterladen, verwalten, starten. Alles über eine saubere Oberfläche. Aktuell läuft bei mir qwen2.5-coder-7b-instruct für Coding-Aufgaben. Klein genug für flüssige Antworten, groß genug um nützlich zu sein.
Open WebUI - ein Interface für alles
Jetzt brauchte ich noch ein Frontend. Eins, das gut aussieht, Chat-History speichert, Dateien verwalten kann, und mit verschiedenen Backends redet.
Open WebUI macht genau das. Open Source, läuft lokal auf Port 8080, und unterstützt sowohl Ollama-kompatible APIs als auch OpenAI-kompatible Endpoints. Die Oberfläche ist clean, die Chats werden in einer lokalen SQLite-Datenbank gespeichert, und man sieht in den Logs jeden einzelnen Request.
Lokale Modelle über LM Chat einbinden, fertig. Zwei Klicks in den Einstellungen, Modell auswählen, chatten.
Aber lokale 7B-Modelle haben Grenzen. Komplexe Aufgaben, längere Kontexte, und vor allem: Bilder verstehen (Vision). Dafür braucht man mehr Power.
Das fehlende Stück: Cloud-Anbindung
Ich habe ein Anthropic Max-Abo. Claude Opus, Flatrate, keine Token-Kosten. Warum das nicht auch über Open WebUI nutzen? BITTE NICHT NACHMACHEN , oder sei dir das Risiko bewusst!!!
Das Problem: Open WebUI spricht OpenAI-Format. Anthropic spricht Anthropic-Format. Und mein KI-System (OpenClaw) läuft als Agent mit eigener Logik. Nicht als simpler API-Proxy.
Die Lösung: Ein kleiner Python-Server. 50 Zeilen Code. Er sitzt auf Port 3200, nimmt OpenAI-formatierte Requests von Open WebUI entgegen, leitet sie an OpenClaw weiter, und gibt die Antwort im richtigen Format zurück. Inklusive Bilder (Vision).
Ein Sonntagmorgen Debugging-Session, zwei Bugfixes (async with für den Streaming-Client, JSON statt Text-Response), und die Kette stand.
Das Ergebnis: Zwei Wege
Jetzt habe ich in Open WebUI die Wahl:
Weg 1 — Lokal (Privatsphäre, Offline, Kostenlos):
Open WebUI (8080) → LM Chat / Ollama API → lokales Modell auf M1Für schnelle Coding-Fragen, Textarbeit, alles wo ein 7B-Modell reicht. Komplett offline. Null Daten verlassen den Rechner.
Weg 2 — Cloud (Power, Vision, Kontext):
Open WebUI (8080) → Vision-Proxy (3200) → OpenClaw (18789) → AnthropicFür komplexe Aufgaben, lange Kontexte, und Bildanalyse. Läuft über mein Max-Abo. Keine zusätzlichen API-Kosten. BITTE NICHT NACHMACHEN , oder sei dir das Risiko bewusst!!!
Im Alltag: Ich wähle einfach das Modell im Dropdown. Open WebUI routet automatisch den richtigen Weg. Lokal wenn’s reicht, Cloud wenn’s sein muss.
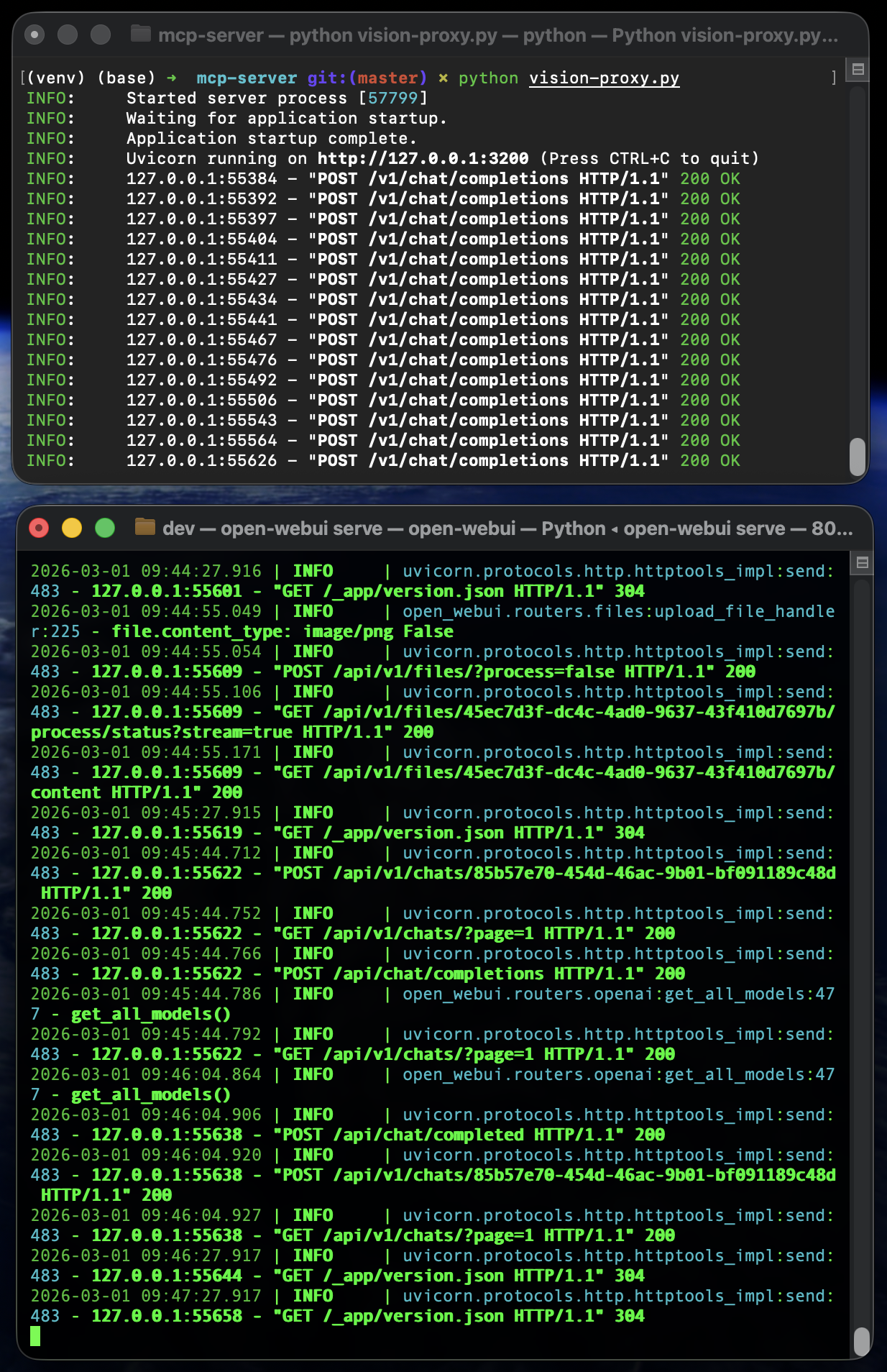
Was man in den Logs sieht
Das Schöne an diesem Setup: Alles ist transparent. Im oberen Terminal laufen die Proxy-Logs. Jeder Request ein grünes 200 OK. Im unteren Terminal loggt Open WebUI jeden Chat, jede gespeicherte Konversation mit UUID. Wenn etwas nicht funktioniert, sehe ich sofort wo es hängt.
Keine Black Box. Kein “Vertrau uns, wir speichern nichts”. Ich sehe was passiert, weil alles auf meinem Rechner läuft.
Was ich gelernt habe
-
Hardware Angelegenheit. Ein M1-Chip macht bei lokalen LLMs den Unterschied zwischen “unbenutzbar” und “flüssig”. Wenn dein Rechner keine GPU hat, such dir einen der sie hat.
-
Das Interface ist entscheidend. Modelle im Terminal abfragen funktioniert, aber Open WebUI macht es erst alltagstauglich. History, File-Management, Modell-Switching.
-
Manchmal reichen 50 Zeilen. Der Vision-Proxy ist kein Riesenprojekt. Er ist ein schlankes Stück Code das zwei Welten verbindet. Nicht alles muss ein Framework sein.
-
Zwei Wege sind besser als einer. Lokal für Privatsphäre und Geschwindigkeit. Cloud für Power. Das eine schließt das andere nicht aus. Mein Motto, sowohl als auch !
Das Setup läuft. Die Tools sind Open Source. Der Proxy ist 50 Zeilen Python. Das einzige was man braucht: einen freien Sonntagmorgen und die Bereitschaft, ein bisschen zu basteln.
Tools: Open WebUI · LM Chat · OpenClaw · Python/FastAPI
Datenaufbewahrung bei Claude: API vs. Web-Interface
Claude API (OpenClaw, CLI, eigene Scripts):
Anthropic speichert API-Prompts und Responses seit September 2025 7 Tage auf ihren Servern – nicht nur flüchtig im RAM, aber auch nicht dauerhaft. Eine Zero Data Retention (ZDR) mit gar keiner Speicherung ist für Enterprise-Kunden verfügbar. API-Daten werden nie für das Modell-Training verwendet.
Claude Web (claude.ai):
Hier speichert Anthropic die Konversationsdaten 30 Tage (Opt-out) oder bis zu 5 Jahre (bei Opt-in für Training). Seit September 2025 müssen Nutzer aktiv zustimmen, damit ihre Daten für das Training genutzt werden dürfen.
Self-hosted Bots (OpenClaw):
Während Anthropic bei API-Nutzung nur 7 Tage speichert, behalten selbst gehostete Bots wie OpenClaw die Daten lokal persistent in Memory-Dateien und Logs. Wer OpenClaw nutzt, sollte beachten: Die Nutzung funktioniert nur mit einem API-Key – Consumer-Abos (Pro, Max) dürfen laut Terms of Service nicht in Drittanbieter-Tools verwendet werden.
- Claude API 7 Tage Aufbewahrung: https://www.datastudios.org/post/claude-data-retention-policies-storage-rules-and-compliance-overview
- Claude API 7 Tage (Bestätigung): https://www.spurnow.com/en/blogs/claude-api-guide
- Claude Web 30 Tage / 5 Jahre & Opt-in für Training: https://www.anthropic.com/news/updates-to-our-consumer-terms
- Claude Web 5 Jahre Aufbewahrung: https://www.theregister.com/2025/08/28/anthropic_five_year_data_retention/
- OpenClaw Terms-of-Service-Verbot für Consumer-Abos: https://www.theregister.com/2026/02/20/anthropic_clarifies_ban_third_party_claude_access/
- OpenClaw Datensicherheit: https://www.ronforbes.com/blog/give-your-personal-ai-assistant-hands-like-openclaw
Datenaufbewahrung bei OpenAI ChatGPT
ChatGPT Web (Free/Plus/Pro):
OpenAI speichert ChatGPT-Konversationen unbegrenzt in der Chat-Historie, bis der Nutzer sie manuell löscht. Nach der Löschung werden die Daten innerhalb von 30 Tagen aus den Systemen entfernt – es sei denn, es liegt eine rechtliche Anordnung vor. Seit Juni 2025 (aufgrund einer Gerichtsanordnung im NYT-Rechtsstreit) muss OpenAI alle ChatGPT-Daten unbegrenzt aufbewahren, auch bereits gelöschte Chats. Diese unbegrenzte Speicherung gilt für Free, Plus, Pro und Team sowie die Standard-API. ChatGPT Enterprise, Edu und API-Kunden mit Zero Data Retention sind davon ausgenommen.
OpenAI API:
Standardmäßig werden API-Inputs und Outputs für 30 Tage aufbewahrt, um den Service zu erbringen und Missbrauch zu erkennen. Nach 30 Tagen werden sie gelöscht. Für Enterprise-Kunden ist Zero Data Retention (ZDR) verfügbar.
Training:
Nutzer können in den Data Controls auswählen, ob ihre Konversationen für das Modell-Training verwendet werden dürfen. Bei Enterprise, Team und API ist das Training standardmäßig deaktiviert.
Quellen:
- ChatGPT Web Retention & Löschfristen: https://help.openai.com/en/articles/8983778-chat-and-file-retention-policies-in-chatgpt
- NYT-Rechtsstreit / Unbegrenzte Aufbewahrung: https://openai.com/index/response-to-nyt-data-demands/
- ChatGPT Daten-FAQ: https://community.openai.com/t/how-long-does-chatgpt-remember-my-data-accurate-privacy-information/1142199
- Unbegrenzte Aufbewahrung inkl. gelöschter Chats: https://the-decoder.com/openai-starts-retaining-all-chatgpt-user-data-including-deleted-chats-and-api-data/
- Datenaufbewahrungspolitik 2025: https://www.datastudios.org/post/chatgpt-data-retention-policies-updated-rules-and-user-controls-in-2025
- Training Opt-Out: https://secureprivacy.ai/blog/gpt-5-training-data-opt-out
- API Batch Datenaufbewahrung: https://community.openai.com/t/data-retention-for-batches/770572